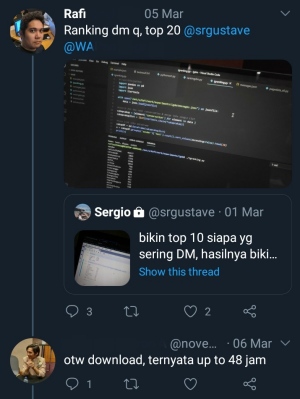
Semua bermula ketika saya lagi bersih-bersih file dan folder di laptop saya. Saya nemu folder arsip data akun instagram saya yang sudah saya download sejak tahun 2018. Di dalamnya ada file messages.json yang membuat saya penasaran pengin baca. File messages.json ini isinya data Direct Messages akun instagram kita. Isinya lengkap mulai dari siapa, teks pesan, gambar/gif yang dikirim, dan lainnya. Karena iseng, akhirnya saya penasaran pengin ngulik data isi DM ini 🧐.
Lihat isi data dalam file
Sebelum saya memilih mau saya apakan data ini, saya cari tahu dulu data ini isinya seperti apa. Karena saya lumayan jago urusan data analisis pake Python, jadi saya pilih pake jupyter notebook sebagai tool buat ngulik.
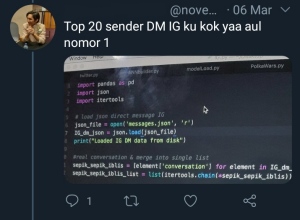
import pandas as pd
dm = pd.read_json('messages.json')
#menyeleksi hanya bagian isi dm
hasil = []
for pesan in dm['conversation']:
for item in pesan[1:]:
hasil.append(item)
isi_dm = pd.Dataframe(hasil)
#print dataframe isi dm
isi_dm.head()Setelah disajikan dalam bentuk dataframe, baru kelihatan kalau datanya punya 20 kolom. Tiap-tiap kolom ini berisi instansi informasi yang terkandung dalam isi DM. Dari 20 instansi yang ada saya hanya akan mengambil 3 instansi saja, yaitu created_at, sender, dan text.
df = isi_dm.copy()
#menghapus kolom yang tidak digunakan
df.drop(
[
'action',
'animated_media_images',
'heart',
'is_random',
'likes',
'link',
'media',
'media_owner',
'media_share_caption',
'media_share_url',
'media_url',
'mentioned_username',
'profile_share_name',
'profile_share_username',
'story_share',
'user',
'video_call_action',
],
(axis = 1),
(inplace = True)
)
#print hasil top 10 orang yang sering DM kita
df.group('sender')['text'].count().sort_values(ascending=False).head(10)Hasil yang didapatkan sebagai berikut:
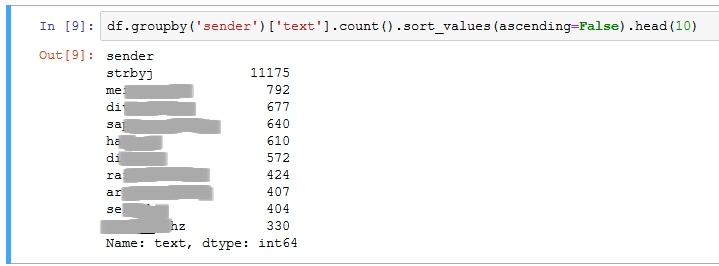 hasilnya bikin saya kaget karena muncul akun yang tidak saya antisipasi 😅😅
hasilnya bikin saya kaget karena muncul akun yang tidak saya antisipasi 😅😅
Peringkat pertama adalah dari akun saya sendiri.
Kok bisa gitu? 🤔
Dataframe yang saya bentuk sengaja menggabungkan seluruh percakapan dari semua orang menjadi satu.
Struktur data asli dari file messages.json seperti ini:
{}
└── {1}
| ├── participants
| | ├── {temen_saya}
| | └── {saya}
| |
| └── conversation
| ├── {isi_DM_1}
| ├── {isi_DM_2}
| ├── {isi_DM_3}
| ├── {...}
|
├── {2}
├── {...}Saya ubah menjadi seperti ini:
{}
├── {isi_DM_1}
├── {isi_DM_2}
├── {isi_DM_3}
├── {isi_DM_4}
├── {isi_DM_5}
├── {isi_DM...}Setelah {isi_DM} digabung menjadi satu thread, otomatis informasi sender (yang ada di dalam {isi_DM}) paling banyak adalah dari si pemilik akun.
Text Processing
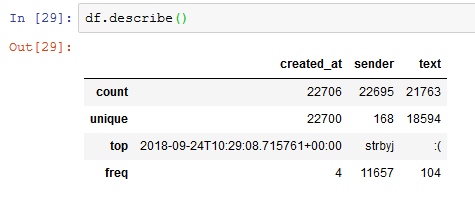
Hal menarik lain yang sebenarnya bisa diulik dari data ini adalah memetakan kata yang sering muncul. Pada gambar di atas, kata yang sering muncul adalah :( yang dikirimkan oleh akun strbyj yaitu saya sendiri (ckckck macam sadboy saja 😥😥). Tetapi untuk melakukan pemetaan dengan lebih akurat perlu dilakukan tahapan tambahan yaitu text cleaning. Sayangnya saya belum menemukan modul python text cleaning untuk Bahasa Indonesia.
Everyone join the party 🎉💃🏼
Kembali ke gambar tweet saya di atas, setelah saya membagikan tweet tersebut, beberapa senior dan teman saya menjadi penasaran untuk mencoba mengulik arsip data akun instagram mereka masing-masing.